{authors.length > 0 &&
}
{authors.map(slug => {
const {name, url, avatarUrl} = resolveAuthor(slug);
const inner = <>
{avatarUrl &&  }
{name}
;
return url ?
{inner}
: {inner};
})}
}
{name}
;
return url ?
{inner}
: {inner};
})}
}
{authors.length > 0 && formattedDate && }
{formattedDate && {formattedDate}}
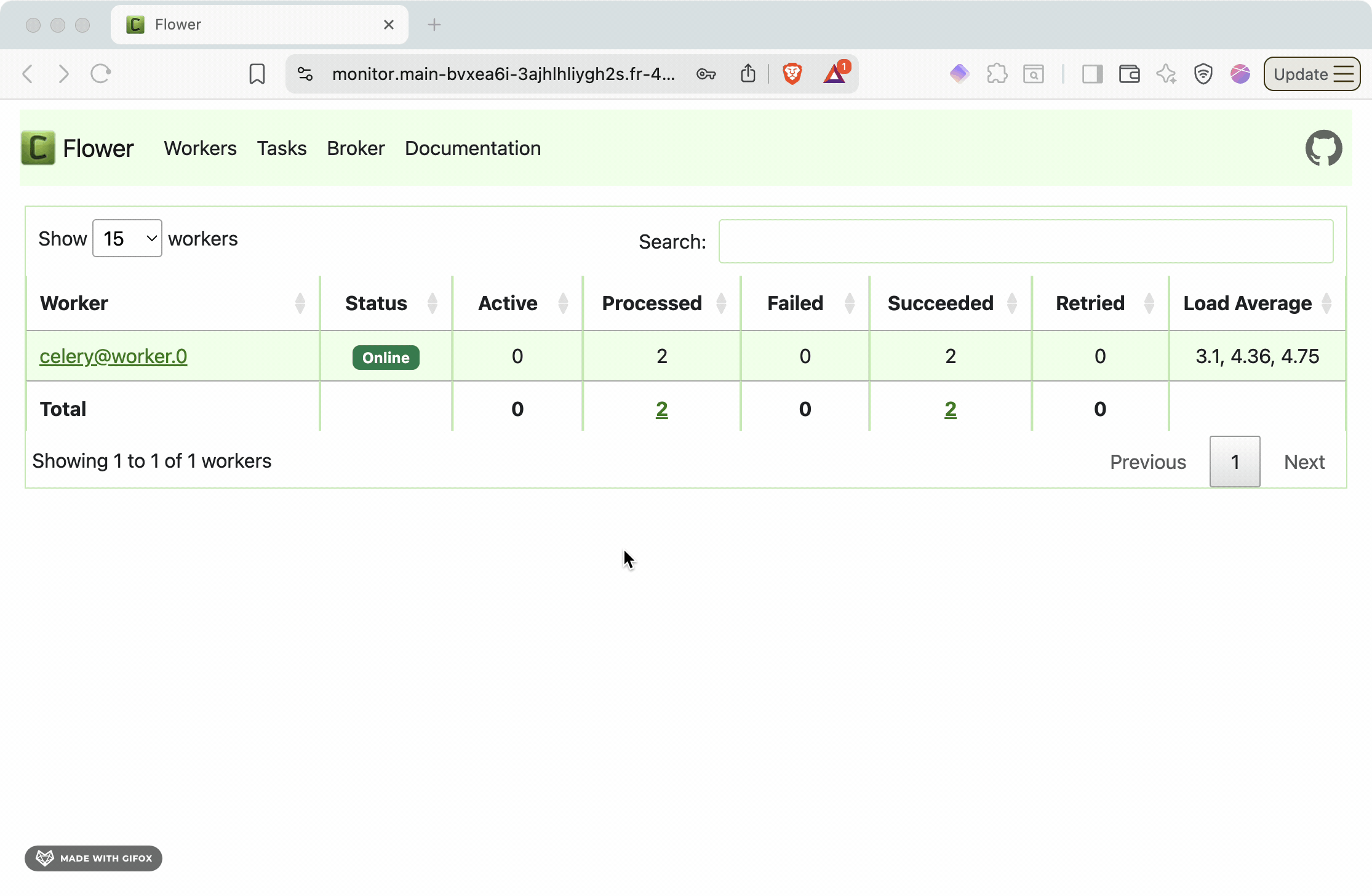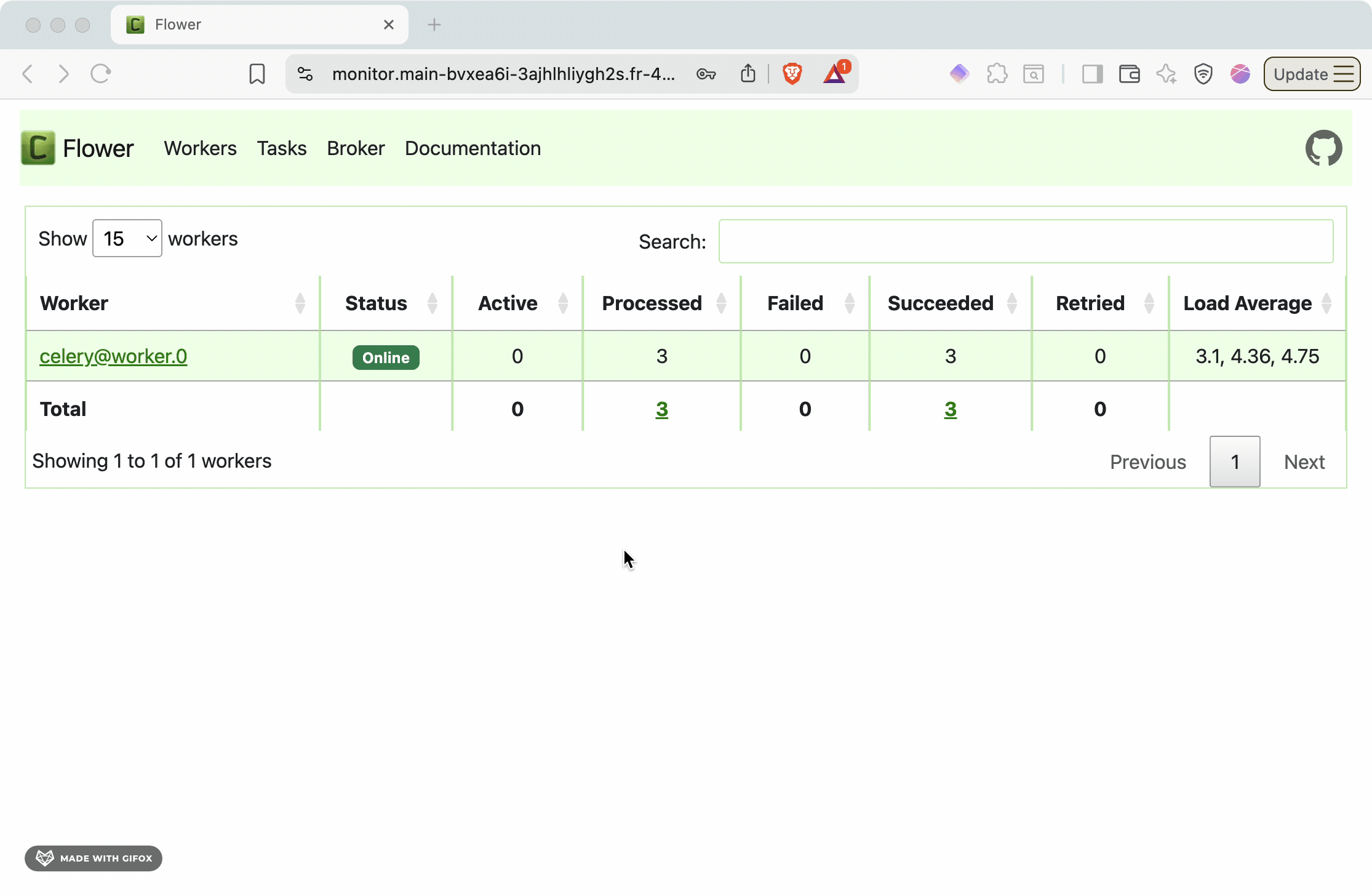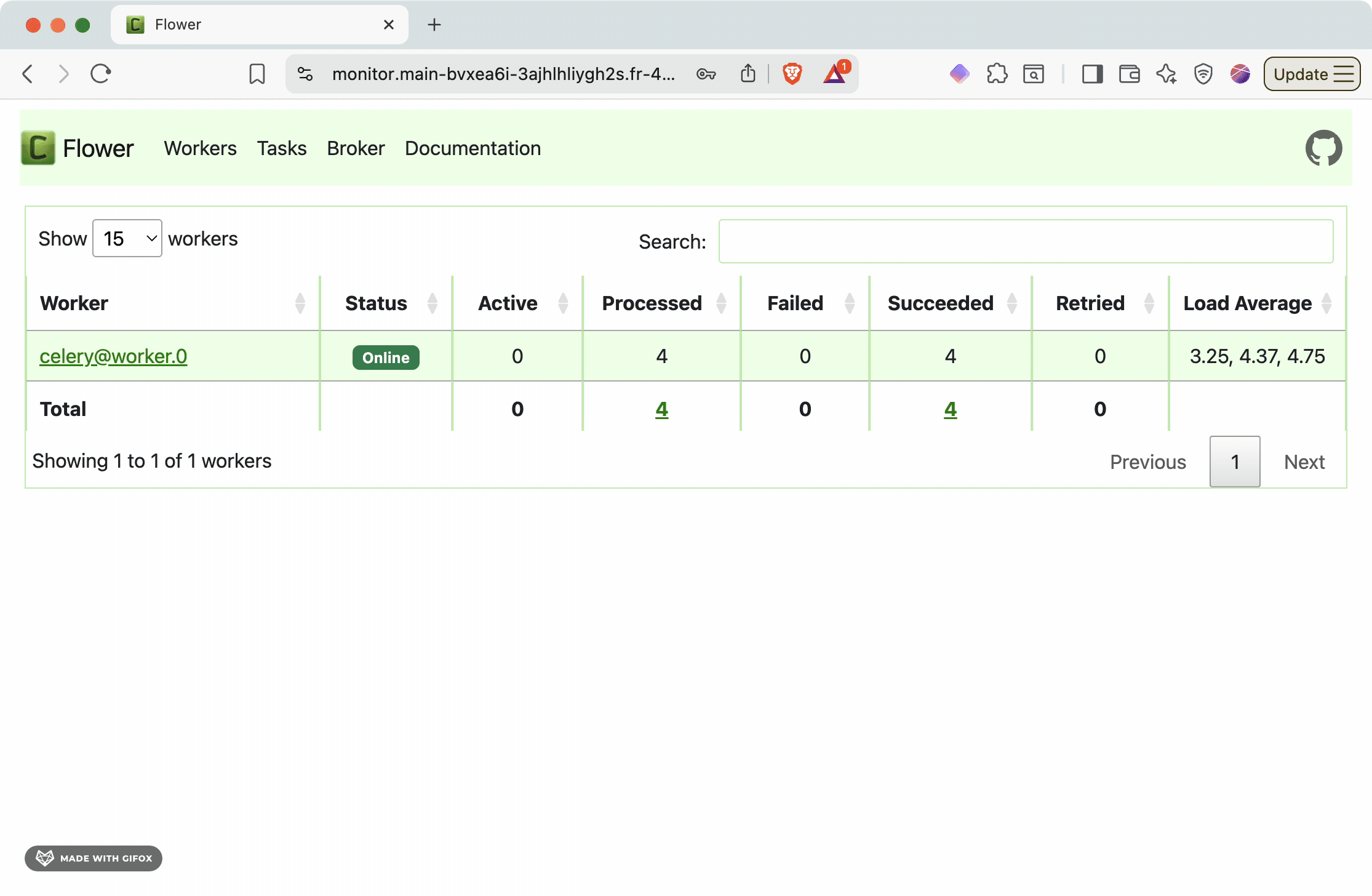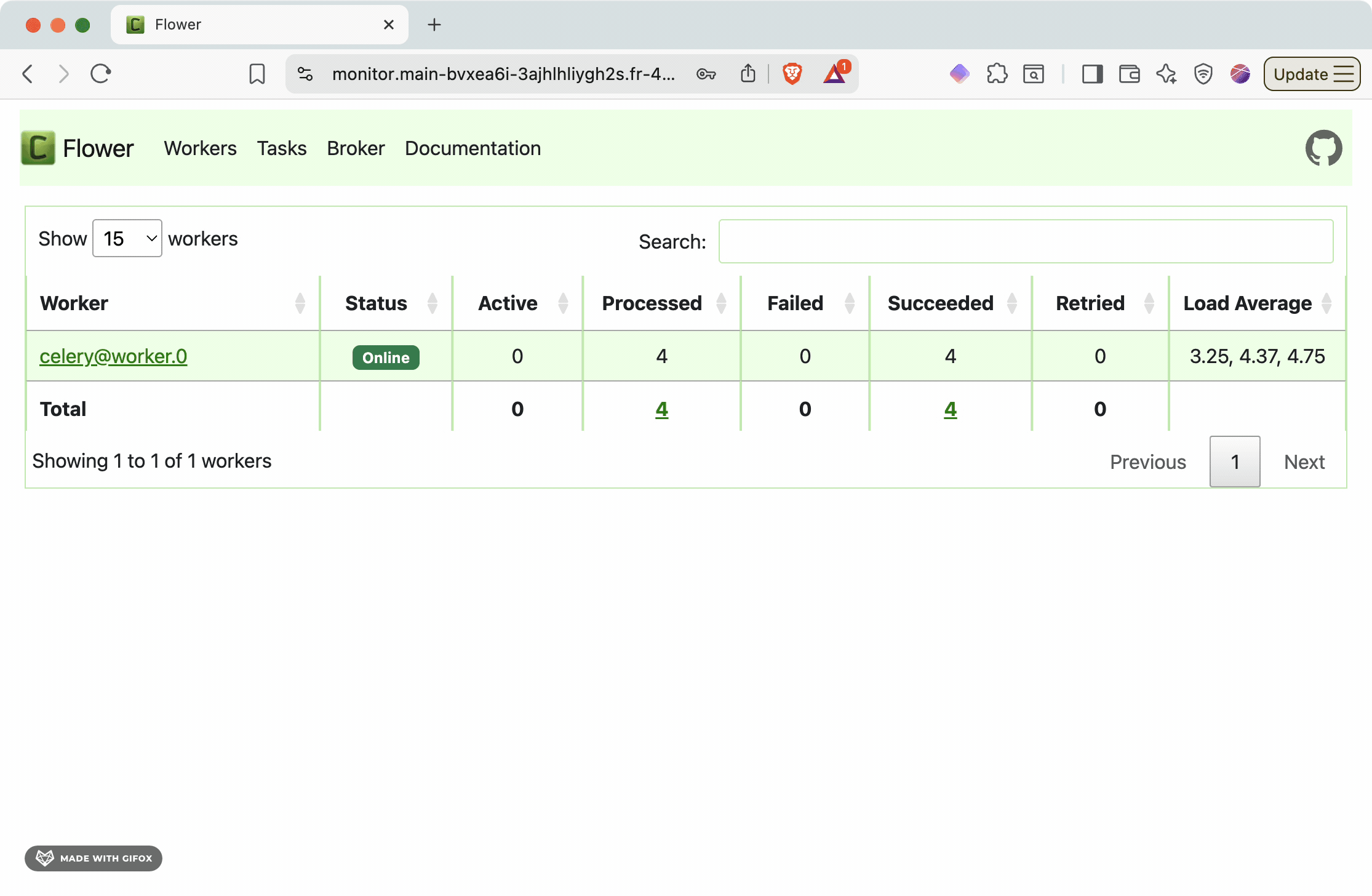 The Flower dashboard provides:
* **Active tasks**: Currently running background jobs
* **Worker status**: Health and performance of Celery workers
* **Task history**: Completed, failed, and retried tasks
* **Queue depth**: Number of pending tasks waiting for processing
* **Performance metrics**: Task throughput, execution times, and success rates
This monitoring capability is essential for production operations, helping you identify bottlenecks, monitor system health, and debug task processing issues.
## Taking your async pipeline to production
### Performance improvements achieved
The async processing approach delivers significant performance gains:
**Response time improvements**: API endpoints respond in milliseconds instead of seconds. Tasks that previously blocked requests for 10-15 seconds now return immediately with a task ID, allowing users to continue using your application.
**Throughput scaling**: With background processing, your API can handle hundreds of concurrent requests while tasks process independently. This separation of concerns prevents processing bottlenecks from affecting user-facing operations.
**Resource efficiency**: Celery workers can run with different CPU and memory allocations than your web processes, optimizing resource utilization. You can scale workers independently based on queue depth rather than web traffic.
**Reliability through isolation**: Individual task failures don't impact other operations. The multi-app architecture ensures that worker crashes or heavy processing loads don't affect API responsiveness.
### Ready to build your async pipeline?
The combination of FastAPI, Celery, and Upsun's multi-app architecture provides everything you need to build production-ready async processing systems. You get the performance benefits of background processing, the reliability of battle-tested tools, and the operational simplicity of managed infrastructure.
[Get started with Upsun](https://upsun.com) and transform your long-running tasks from user experience bottlenecks into seamless background operations.
The Flower dashboard provides:
* **Active tasks**: Currently running background jobs
* **Worker status**: Health and performance of Celery workers
* **Task history**: Completed, failed, and retried tasks
* **Queue depth**: Number of pending tasks waiting for processing
* **Performance metrics**: Task throughput, execution times, and success rates
This monitoring capability is essential for production operations, helping you identify bottlenecks, monitor system health, and debug task processing issues.
## Taking your async pipeline to production
### Performance improvements achieved
The async processing approach delivers significant performance gains:
**Response time improvements**: API endpoints respond in milliseconds instead of seconds. Tasks that previously blocked requests for 10-15 seconds now return immediately with a task ID, allowing users to continue using your application.
**Throughput scaling**: With background processing, your API can handle hundreds of concurrent requests while tasks process independently. This separation of concerns prevents processing bottlenecks from affecting user-facing operations.
**Resource efficiency**: Celery workers can run with different CPU and memory allocations than your web processes, optimizing resource utilization. You can scale workers independently based on queue depth rather than web traffic.
**Reliability through isolation**: Individual task failures don't impact other operations. The multi-app architecture ensures that worker crashes or heavy processing loads don't affect API responsiveness.
### Ready to build your async pipeline?
The combination of FastAPI, Celery, and Upsun's multi-app architecture provides everything you need to build production-ready async processing systems. You get the performance benefits of background processing, the reliability of battle-tested tools, and the operational simplicity of managed infrastructure.
[Get started with Upsun](https://upsun.com) and transform your long-running tasks from user experience bottlenecks into seamless background operations.