{authors.length > 0 &&
}
{authors.map(slug => {
const {name, url, avatarUrl} = resolveAuthor(slug);
const inner = <>
{avatarUrl &&  }
{name}
;
return url ?
{inner}
: {inner};
})}
}
{name}
;
return url ?
{inner}
: {inner};
})}
}
{authors.length > 0 && formattedDate && }
{formattedDate && {formattedDate}}
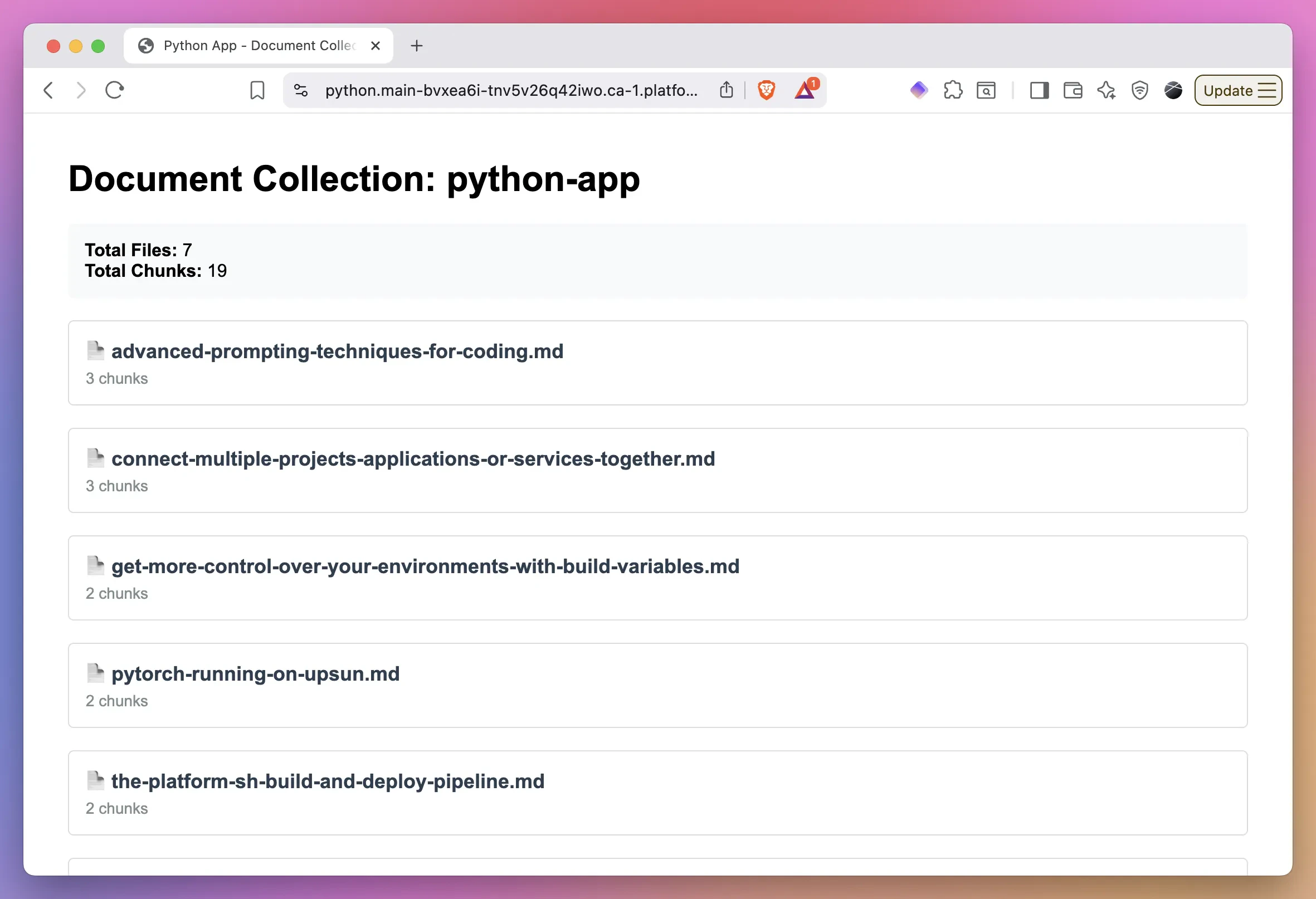 ### Node.js app:
### Node.js app:
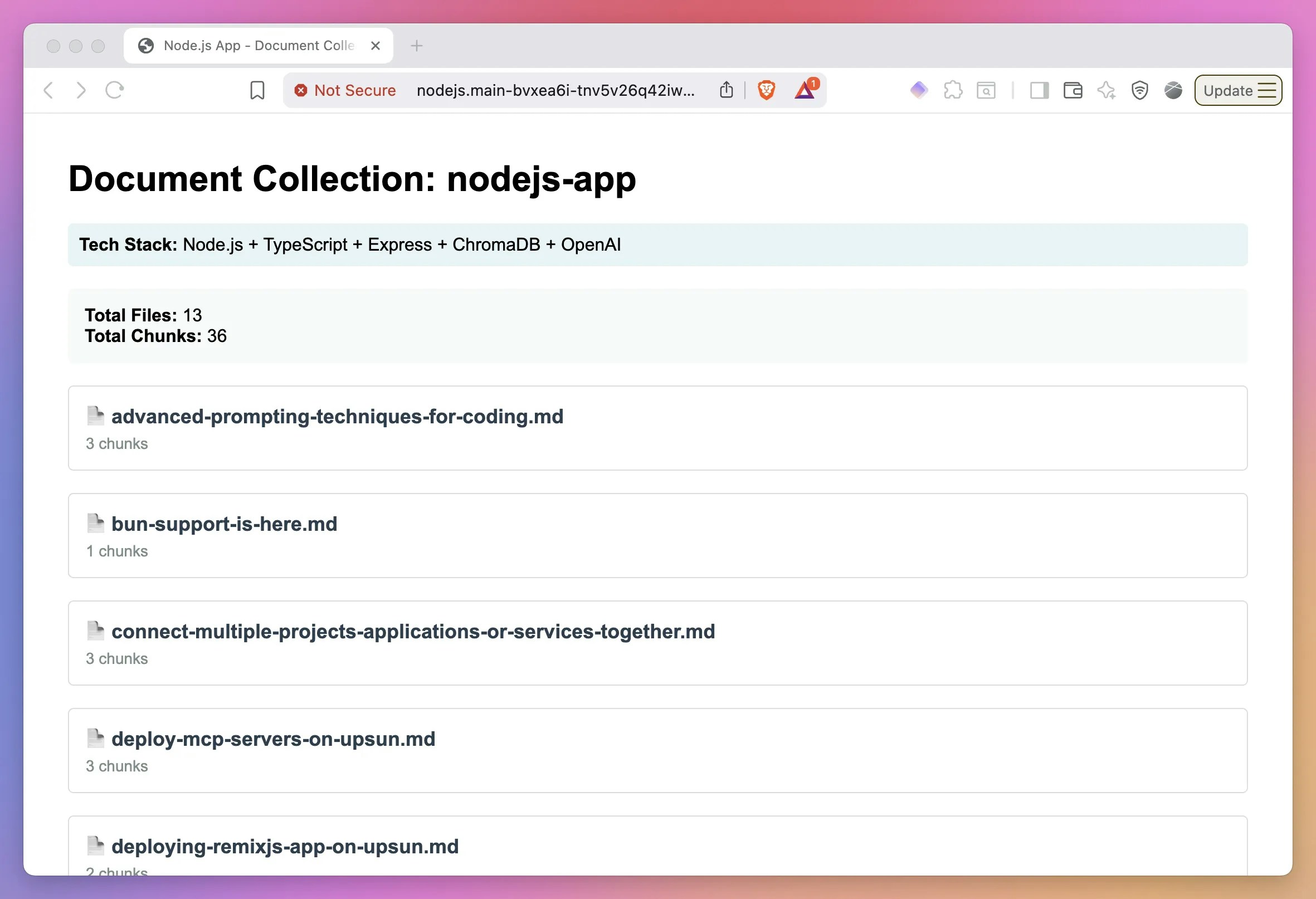 Both applications will display the ingested documents and their chunk counts, demonstrating successful embedding storage in Chroma with persistent storage across deployments.
Both applications will display the ingested documents and their chunk counts, demonstrating successful embedding storage in Chroma with persistent storage across deployments.